Stop AI Spend Before It Crosses the Limit
Cloptima applies low-latency LLM budget checks in the request path and keeps the final usage trail ready for reporting and reconciliation workflows.
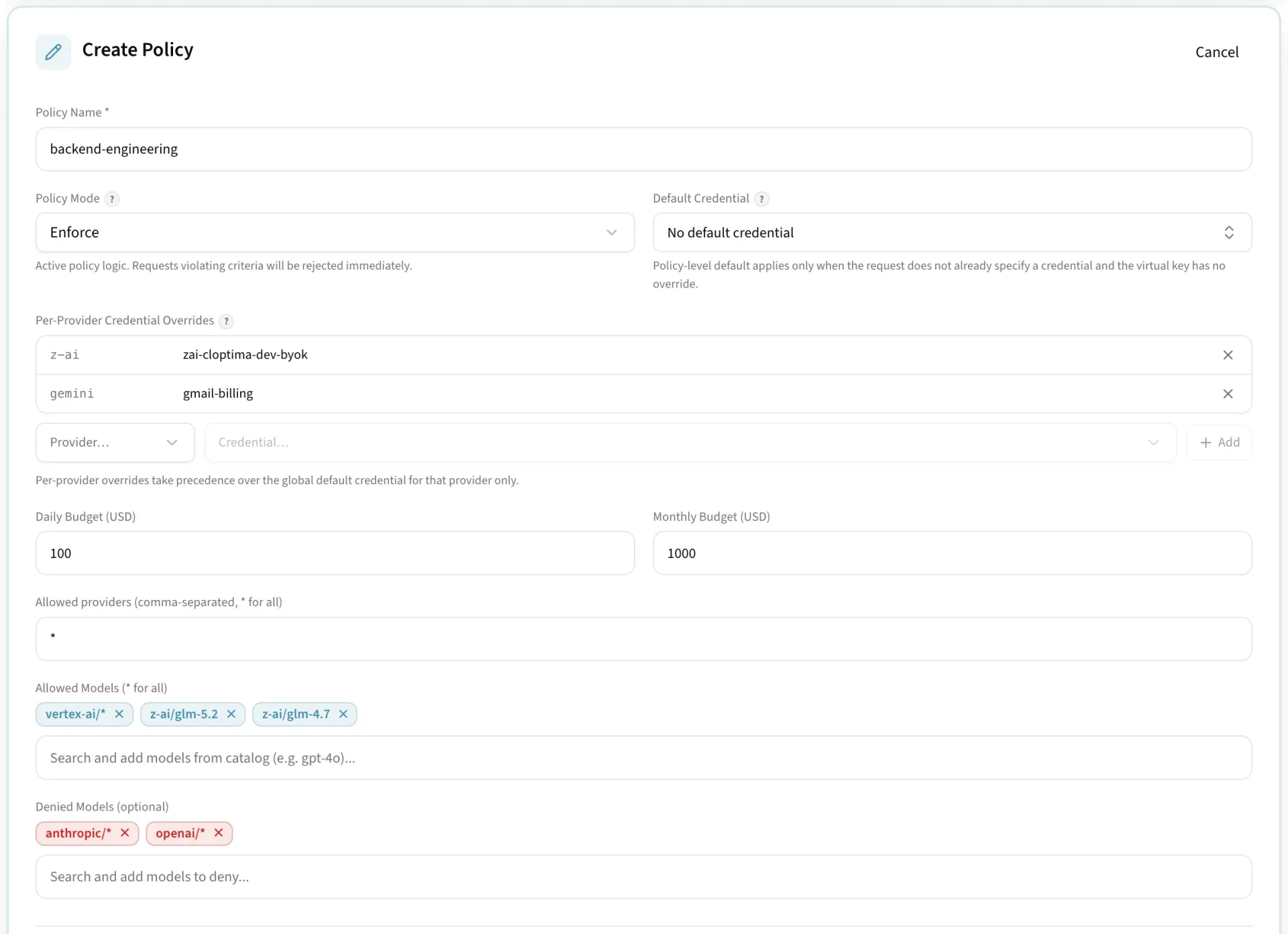
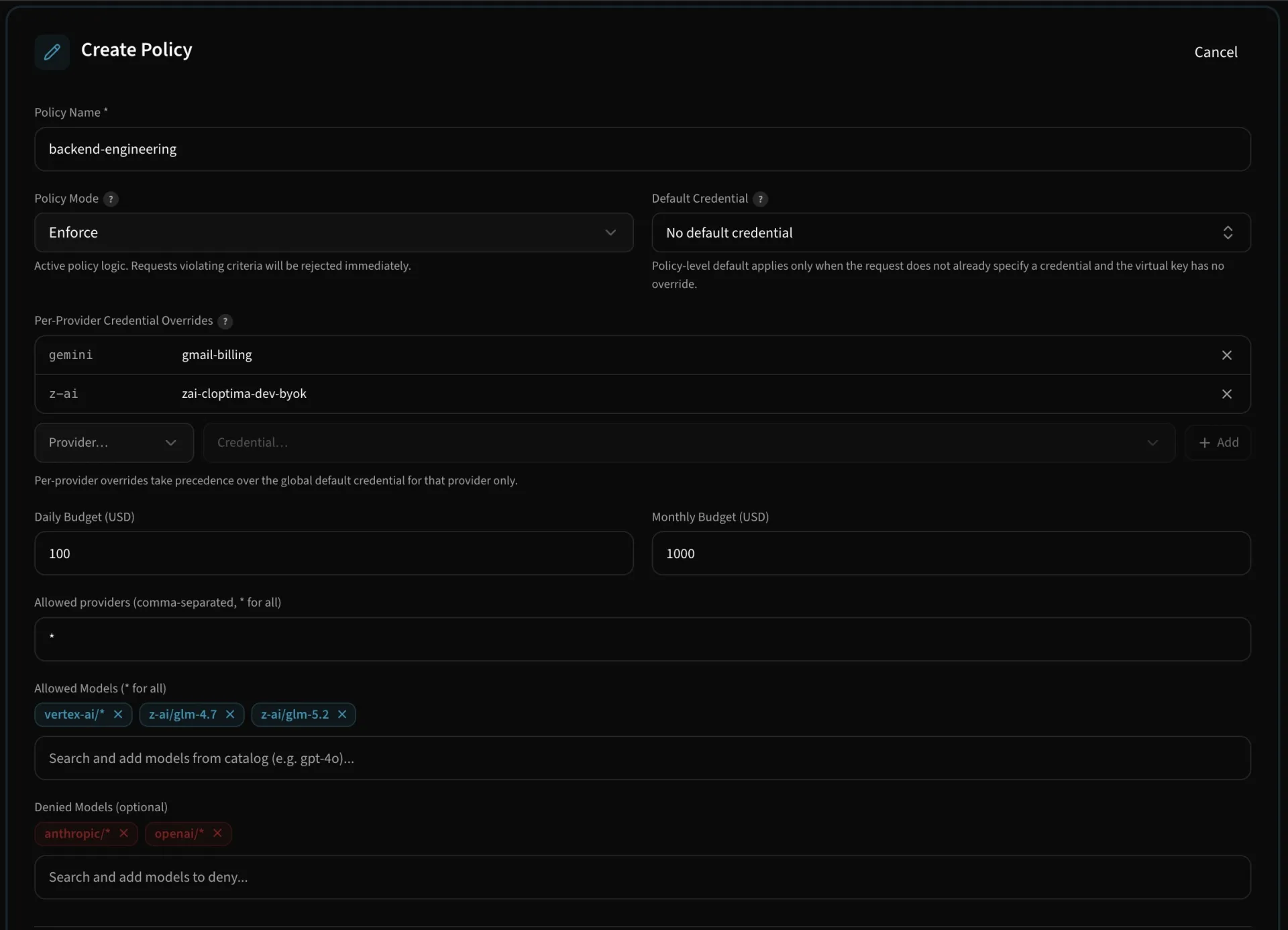
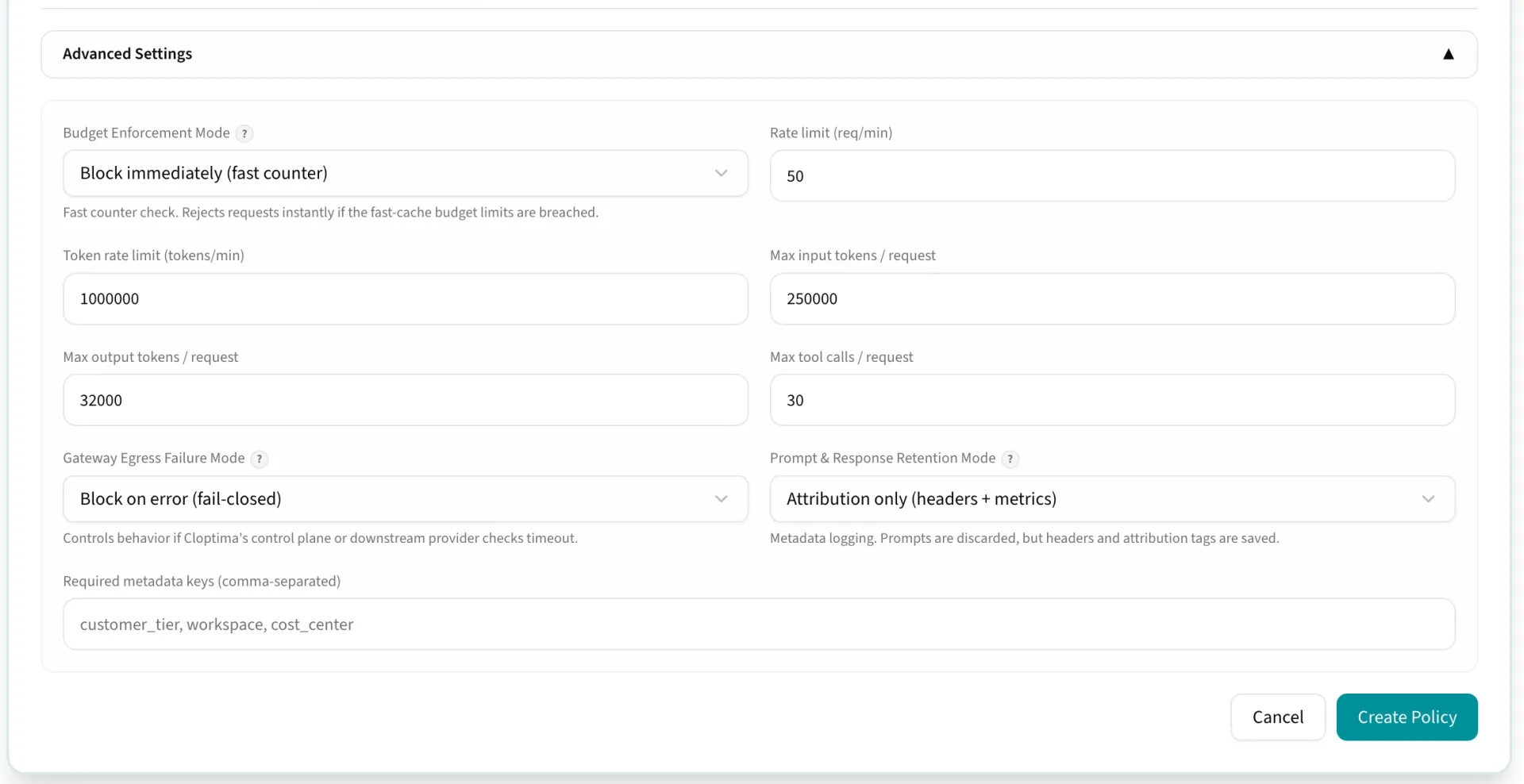
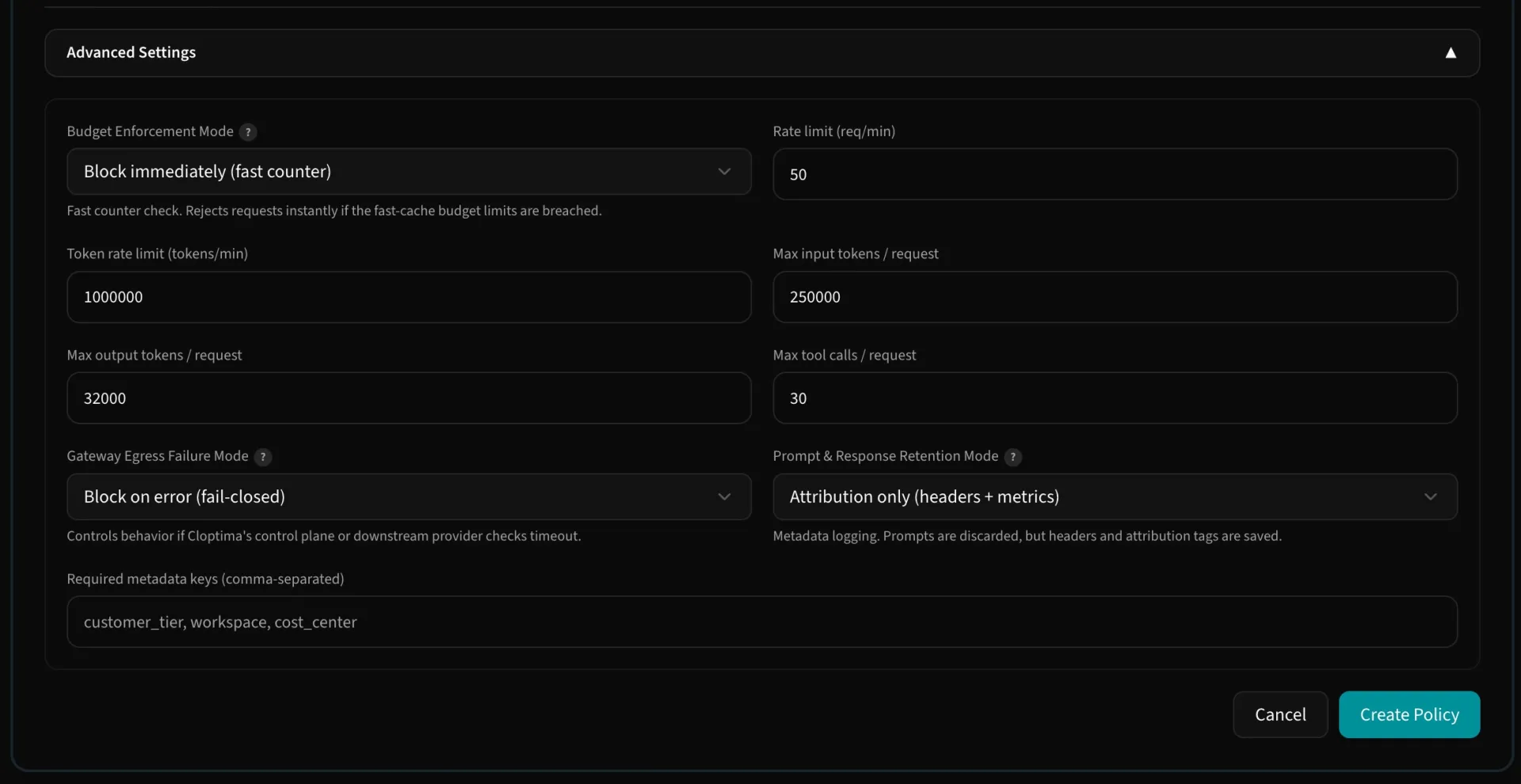
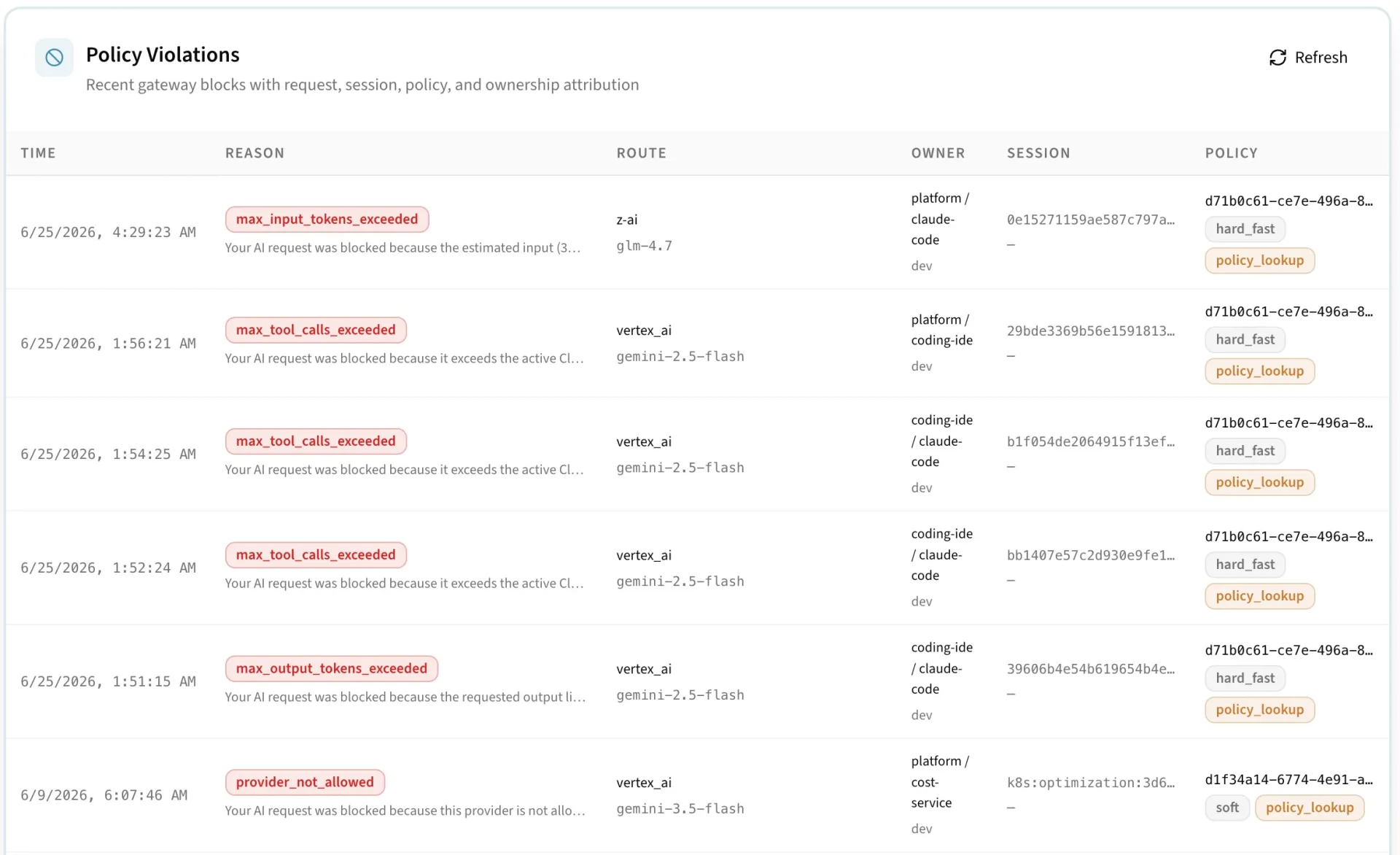
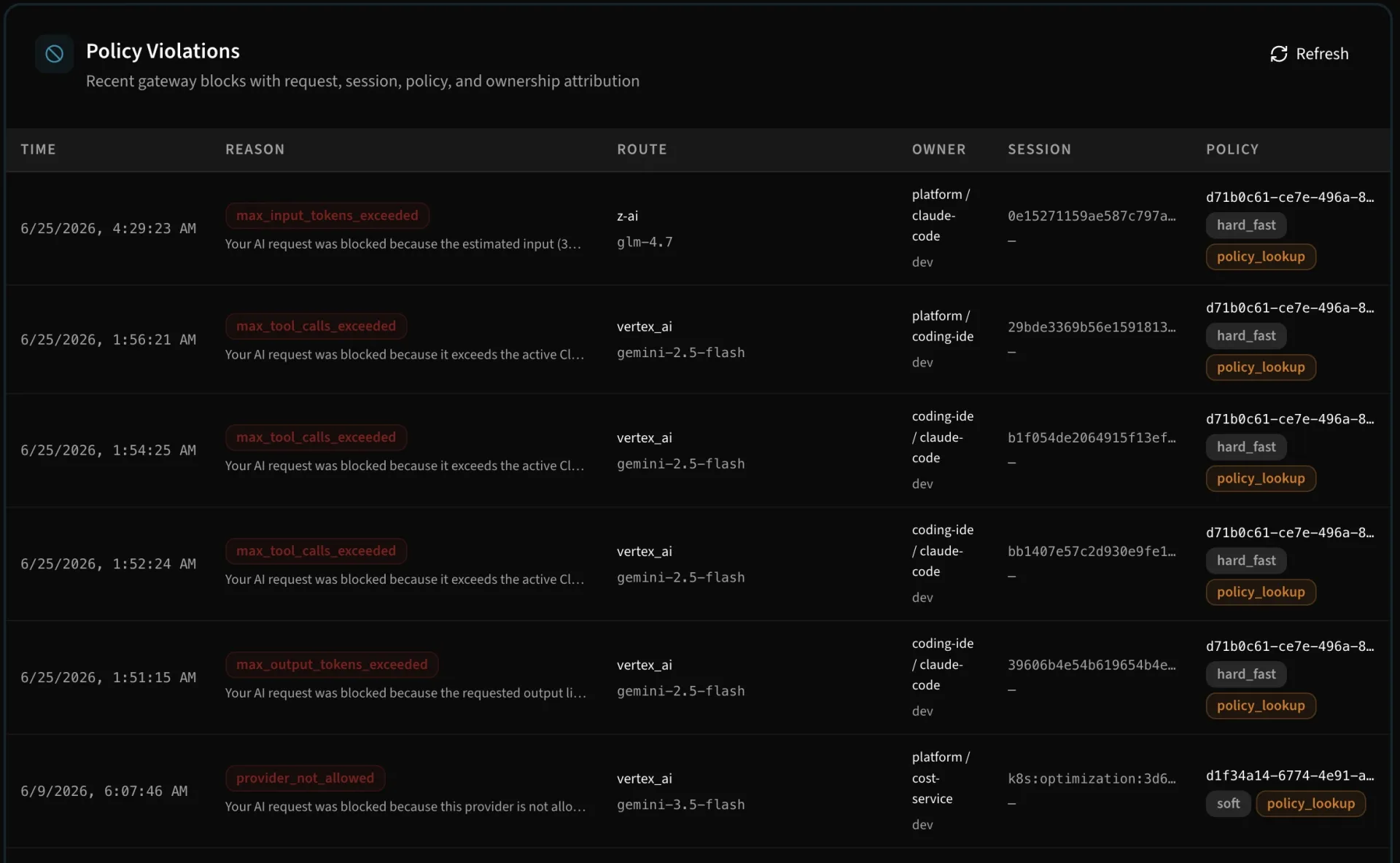
Govern access before spend happens
Traditional budget alerts arrive after usage already happened. LLM workloads need controls that can stop runaway loops, unexpected model upgrades, and high-volume experiments before they become material spend.
One policy layer across model usage
Policies can enforce spend, token, and request ceilings across providers and dimensions. Cloptima tracks reservations before a call and finalizes usage after the response so dashboards stay close to real usage.
- Team and app budgets
- Provider and model limits
- Environment-specific controls
- Agent session and run-level governance
Start with one app, then expand
Create default development limits, protect production with higher thresholds, and require approval before teams use expensive models or unusually large context windows.
Built for private production AI
Budget enforcement is built around fast pre-flight checks, durable reservations, and usage finalization. That lets Cloptima avoid relying only on delayed logs or monthly provider exports.
Launch path
Define policy scopes, set monthly and daily limits, bind policies to virtual keys or teams, and review over-limit events from the audit view.
FAQ
Operationalize LLM FinOps Across Your Apps
Start with telemetry, gateway governance, or provider bill matching workflows. Keep model spend connected to engineering ownership and finance reporting.